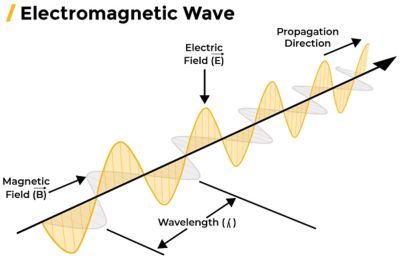


















Create Reliable and Efficient Designs With Production-Proven Multiphysics Analysis
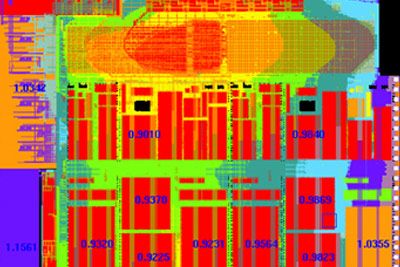
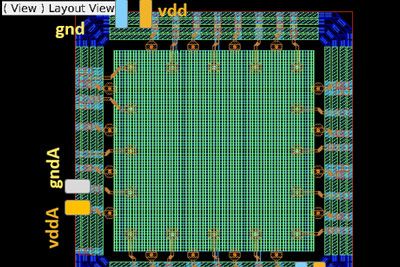
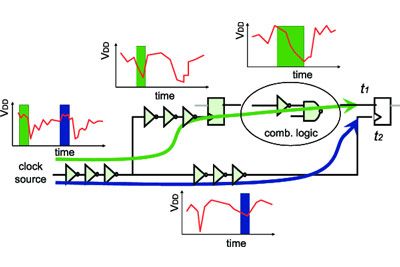
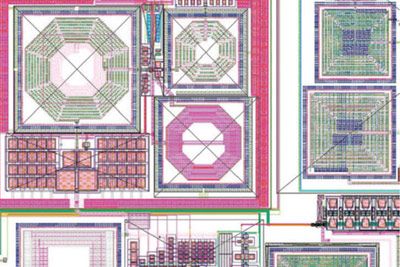
Ansys cloud-native solutions provide unparalleled capacity to speed up completion times for even the largest finFET integrated circuits (IC) and 3D/2.5D multi-die systems. These powerful multiphysics analysis and verification tools reduce power consumption, improve performance and reliability, and lower project risk with foundry-certified golden signoff verification.